과목4. 데이터베이스 구축, 14강. 물리 데이터베이스 설계-물리요소 조사 분석
[ 목차 ]
1. 스토리지
2. DAS (direct attached storage)
3. NAS(network attached storage)
4. SAN(storage area network)
5. 분산 데이터베이스
6. 분산 데이터베이스 목표
7. 분산 데이터베이스의 장점
8. 분산 데이터베이스의 단점11. 테이블 분할 분산(fragmentation)
9. 분산 데이터베이스 적용 기법
10. 테이블 위치 분산
12. 테이블 복제 분산
13. 테이블 요약 분산
14. 데이터베이스 분산구성의 가치
15. NoSQL(not only sql)
16. 노에스큐엘 특징
17. 노에스큐엘의 저장구조 - key/value store (출제 가능성 낮음)
18. 데이터베이스의 이중화
19. active-active
20. active-standby
21. 이중화의 활용
22. 데이터베이스 암호화
23. DB 암호화 방식
24. 디스크 전체(storage level) 암호화
25. 칼럼 레벨 암호화(column level) 암호화
26. 접근 통제
27. 임의 접근 통제
28. 강제 접근 통제
29. 역할기반 접근 통제
30. 접근 통제와 dcl의 관계
31. db 접근 통제 구성방법
32. 게이트웨이
33. 스니핑 방식
34. 에이전트 방식
35. 하이브리드 방식
36. 비교
37. 접근 통제 매커니즘
1. 스토리지
1) 대용량 데이터를 저장하기 위해 구성된 시스템
2) DAS, NAS, SAN
2. DAS (direct attached storage)
1) 서버와 저장 장치를 전용 컨트롤러와 케이블을 이용해 직접 연결하는 방식
2) 저렴한 비용, 빠른 속도, 쉬운 설치와 운영
3) 데이터가 크지 않고 공유가 필요하지 않은 환경에 적합
4) 서버간 디스크가 분리되어 있어 저장 장치 영역에서는 스토리지, 파일 공유가 어려움
5) 서버가 다운되는 경우 해당 저장 장치 사용 불가
6) 계속된 저장 장치 추가는 성능 저하 유발

3. NAS(network attached storage)

1) 서버와 저장장치를 네트워크로 연결
2) 구성 설정이 간편
3) 별도의 운영 체제를 가진 서버 한곳에서 파일을 관리하기 때문에 서버간 스토리지, 파일 공유가 용이
4) 네트워크 환경 상태에 영향을 받아 불안정할 경우 데이터 처리에 영향
5) 대용량 트랜잭션 처리로 인해 네트워크 상태에 영향
4. SAN(storage area network)

1) DAS의 빠른 처리와 NAS의 스토리지 공유 장점을 합침
2) 스토리지 전용 네트워크로 컴퓨터 간을 연결하는 구내 정보 통신망과는 달리 하드 디스크 등의 외부 기억 장치끼리 고속으로 연결된 통신망
3) 광케이블(FC)과 광채널 스위치를 통해 근거리 네트워크 환경을 구성하여 빠른 속도로 데이터를 처리
4) 저장 장치 연결로 스토리지 공유가 가능
5) 스토리지 시스템 중 대용량 환경의 높은 트랜잭션 처리에 가장 효과적
6) 기존 시스템 장비에 대한 제약이 있고 SAN 환경 구축 비용이 비쌈
피버 채널(fiber channer, fc. 광섬유 채널)
1) ANSI가 채택한 차세대 고속 인터페이스
2) 광섬유를 사용한 컴퓨터끼리 또는 컴퓨터와 주변 기기를 접속할 때 화상 등 방대한 데이터를 전송하는 멀티미디어 시대에 대응한 인터페이스
3) SAN에 사용되는 표준화 채널
5. 분산 데이터베이스
1) 하나의 데이터베이스 관리 시스템(DBMS)이 여러 CPU에 연결된 저장장치들을 제어하는 형태의 데이터베이스
2) 논리적으로 같은 시스템에 속하지만 컴퓨터 네트워크를 통해 물리적으로 분산되어 있는 데이터들의 모임
3) 데이터베이스를 연결하는 빠른 네트워크 환경을 이용하여 데이터베이스를 여러 지역 노드로 위치시켜 사용성, 성능 등을 극대화시킨 데이터베이스
6. 분산 데이터베이스 목표
1) 분할 투명성(단편화) : 하나의 논리적 릴레이션이 여러 단편으로 분할(수직 or 수평)되어 각 단편의 사본이 여러 사이트에 저장
2) 위치 투명성 : 데이터의 저장 장소 명시 불필요. 위처정보가 시스템 카탈로그에 유지. 논리적인 입장에서 데이터가 모두 자신의 사이트에 있는 것처럼 처리
3) 지역사상 투명성 : 지역 DBMS와 물리적 DB 사이의 매핑 보장, 각 지역시스템 이름과 무관한 이름 사용 가능
4) 중복 투명성 : DB 객체가 여러 사이트에 중복되어 있는지 알 필요 없는 성질
5) 장애 투명성 : 구성요소의 장애에 무관한 트랜잭션의 원자성 유지(=장애와 무관하게 정확하게 처리)
6) 병행 투명성 : 다수 트랜잭션 동시 수행시 결과의 일관성 유지, 타임스탬프와 분산 2단계 로팅을 이용 구현(=병행 제어 기법)
7. 분산 데이터베이스의 장점
1) 지역 자치성, 점증적 시스템 용량 확장
2) 신뢰성과 가용성
3) 효옹성과 융통성
4) 빠른 응답속도와 봉신비용 절감(공유)
5) 데이터의 가용성과 신뢰성 증가
6) 시스템 규모의 적절한 조절
7) 각 지역 사용자의 요구 수용 증대
8. 분산 데이터베이스의 단점
1) 소프트웨어 개발 비용
2) 오류의 잠재성 증대
3) 처리 비용의 증대
4) 설계, 관리의 복잡성과 비용
5) 불규칙한 응답속도
6) 통제의 어려움
7) 데이터 무결성 위협
9. 분산 데이터베이스 적용 기법
1) 테이블 위치 분산, 테이블 분할 분산, 테이블 복제 분산, 테이블 요약 분산
2) 테이블 복제 분할 분산 방법이 가장 많이 사용되며 검색 성능 저하가 많은 db에서 가장 유용하게 적용 가능
10. 테이블 위치 분산
1) 테이블의 구조가 변하지 않음
2) 테이블이 다른 데이터베이스에 중복되어 생성되지 않음
3) 테이블의 위치를 각각 다르게 위치시키는 것
4) 자제품목은 본사에서 구입, 관리하고 각 지사별로 자재품목을 이용해 제품을 생산

11. 테이블 분할 분산(fragmentation)
1) 단순히 위치만 다른 곳에 두지 않고 각각의 테이블을 쪼개어 분산
2) 테이블의 로우 단위로 분리하는 수평분할과 칼럼 단위로 분위하는 수직분할에 따라 테이블을 분할하여 분산
3) 수평분할 horizontal
1] 지사에 따라 테이블을 특정 칼럼의 값을 기준으로 로우를 분리
2] 칼럼은 분리되지 않음
3] 모든 데이터가 각 지사별로 분리되어 있는 형태
4] 각 지사별로 로우가 다를때 이용

4) 수직분할 vertical
1) 지사에 따라 테이블을 칼럼 기준으로 칼럼을 분리
2) 로우 단위로는 분리되지 않음
3) 모든 데이터가 각 지사별로 분리되어 있는 형태
4) 칼럼을 기준으로 분할하였기 때문에 각각의 테이블에는 동일한 기본키 구조와 값을 지녀야 함
5) 지사별로 또개진 테이블을 조합하면 기본키가 동일한 데이터의 조합이 가능해야 하며 하나의 완전한 테이블이 구성되어야 함
6) 데이터를 한군데 집합시켜 놓아도 동일한 기본키는 하나로 표현하면 되므로 데이터 중복은 발생하지 않음
7) 테이블 전체 칼럼 데이터를 보기 위해서는 각 지사별로 흩어져 있는 테이블을 조인해 가져와야 하기 때문에 가능하면 통합하여 처리하는 프로세스가 많을 경우 사용하지 않음

12. 테이블 복제 분산
1) 동일한 테이블을 다른 지역이나 서버에서 동시에 생성하여 관리하는 유형
2) 마스터 데이터베이스에서 테이블의 일부의 내용만 다른 지역, 서버에 위치시키는 부분복제와 전체 내용을 존재시키는 광역복제가 존재
3) 부분복제 : 통합된 테이블을 본사가 가지고 지사별로는 지사에 해당된 로우를 가지고 있는 형태
4) 광역복제 : 통합된 테이블을 본사가 가지고 있으면서 지사도 본사와 동일한 테이터를 가진 형태로, 본사나 지사 모두 데이터처리에 특별한 제약을 받지 않음
13. 테이블 요약 분산
1) 지역간에 또는 서버 간에 데이터가 비슷하지만 서로 다른 유형으로 존재하는 경우
2) 요약의 방식에 따라 분석요약과 통합요약으로 구분
3) 분석 요약
1] 각 지사별로 존재하는 요약정보를 본사에 통합하여 다시 전체에 대해서 요약 정보를 산출
2] 지사1의 판매 실적과 지사2의 판매 실적을 본사가 통합하여 전체 판매실적을 산출하는 방식
3] 동일한 테이블 구조를 가지고 있으며 분산되어 있는 동일한 내용의 데이터를 이용하여 통합된 데이터를 산출
4] 통합요약
1] 지사별로 존재하는 다른 내용의 정보를 본사에 통합하여 다시 전체에 대해서 요약정보를 산출하는 방법
2] 지사1의 A제품 판매 실적와 지사2의 B제품 판매 실적을 본사가 통합하여 A, B의 전체 판매실적을 산출
14. 데이터베이스 분산구성의 가치
1) 통합된 데이터베이스에서 제공할 수 없는 빠른 성능을 제공
2) 원거리 또는 다른 서버에 접속하여 처리하여 발생되는 네트워크 부하 및 트랜잭션 집중에 ㄷ라느 성능 저하의 원인을 분산 데이터베이스 환경을 구축하여 빠른 성능 제공 가능
15. NoSQL(not only sql)
1) 수평적 확장이 가능하며 다수 서버들에 데이터 복제 및 분산저장이 가능한 데이터베이스
2) 빅데이터 처리를 위한 비관계형 dbms
3) 관계형 데이터베이스를 절대 사용하지 않는다는 것이 아니라 관계형 데이터베이스보다 덜 제한적이고 여러 유형의 데이터베이스를 사용
4) 스키마가 없어 다루기 쉽고 부하의 분산 또한 간편
5) 스키마가 없기 때문에 데이터에 대한 규격화된 결과 값을 얻기 힘듬
6) 관계형 db의 한계에서 벗어나 web2.0의 비정형 초고용량 데이터 처리를 위해 데이터의 읽기보다 쓰기에 중점
web2.0 : 사용자가 직접 데이터를 인터넷상에서 생산하고 공유할 수 있는 인터넷 공간
16. 노에스큐엘 특징
1) schema-less : 고정된 데이터 스키마 없이 키 값을 이용해 다양한 형태의 저장과 접근이 가능하며 칼럼, 값, 문서, 그래포의 저장 방식을 가짐
2) 탄력셩 elasticity : 시스템의 일부 장애에도 다운타임이 없는 동시에 대용량 데이터의 생성, 업데이트, 질의에 대응할 수 있도록 시스템 규모와 성능 확장이 용이하고 입출력의 부하분산에도 용이한 구조를 지님
3) 효율적 질의기능 query : 데이터의 특성에 맞게 효율적으로 데이터를 검색, 처리할 수 잇는 질의언어, 관련 처리기술, API를 제공
4) 캐싱 caching : 대규모의 질의에도 고성능 응답속도를 제공할 수 있는 메모리 기반의 캐싱기술의 적용이 매우 중요하고 개발 및 운영에서도 일관되게 적용할 수 있는 구조
17. 노에스큐엘의 저장구조 - key/value store (출제 가능성 낮음)
1) 가장 기본적인 패턴으로 대부분의 nosql은 다른 데이터모델을 지원하더라도, 기보적으로 key/value 개념을 지원
2) Unique key에 하나의 value를 가지고 있는 형태로 Put(Key, vlaue), value : = get(Key) 형태의 API로 접근
3) Oracle Coherence, Redis에 사용

18. 데이터베이스의 이중화
1) 물리적으로 떨어져 잇는 여러 개의 데이터베이스에 대하여 로컬 데이터베이스의 변경된 내용을 원격데이터베이스에 복제하고 관리하는 것(master-slave 관계)
2) 데이터베이스의 무정지 서비스를 가능하게 함
3) db 서버 2대가 동시에 동작하는 것을 허락하는 방식에 따라 active-active와 active-standby로 나뉨
19. active-active
1) 클러스터를 구성하는 컴포넌트를 동시에 가동하는 구성
2) 시스템 다운 시간이 짧음
3) 성능이 좋음
20. active-standby
1) 클러스터를 구성하는 컴포넌트 중 실제 가동하는 것은 active이며 남은 것은 대기
2) 평소에 standby 서버가 내려가 있는 cold-standby구성과 평소에도 standby가 기동되어 있는 hot-standby가 존재
3) hot standby : standby쪽 장비 기동 후 즉시 사용이 가능하고 failover(장애극복) 소요시간은 필요
4) warm standby : standby쪽 장비 기동 후 이용하기 위해 어느정도 설정과 준비시간 필요
5) codl standby : 평소 정지시켜 두며 필요에 따라 직접 켜서 구성
6) failover 소요시간 : hot < warm < cold
21. 이중화의 활용
1) 장애 : 장비에 장애가 발생하여 1대의 장비가 죽을 시 준비된 장비를 서비스에 투입함으로써 짧은 시간 내에 서비스 복구가 가능
2) 웹서비스의 배포 : 두대의 서버가 LB(부하분산)에 의하여 active-active로 운영되고 있는 경우 한대를 lb에서 제거한 뒤 배포 및 미들웨어 재기동 후 lb에 붙이고 다시 나머지 한대도 똑같이 작업하는 경우 서비스의 다운타임 없이 온라인 배포가능
3) 장비의 점검 : 서버 혹은 네트워크장비를 운영시 os나 software stack 등을 보안이나 기능 추가 등의 이유로 업데이트 및 설정 변경 시 이중화를 이용하면 서비스의 다운타임 없이 점검 가능
22. 데이터베이스 암호화
1) 데이터베이스 보안 : 데이터베이스의 일부분 또는 전체에 대해 권한이 없는 사용자가 접속하는 것을 금지하기 위해 사용되는 접근 통제 기술과 기밀 데이터에 접근하더라도 비밀성을 보장할 수 있도록 데이터를 암호화
2) 뷰를 이용해 데이터 객체에 대한 접근을 통제하는 방법과 DCL문을 이용해 데이터에 대한 접근 권한을 부여하거나 회수하는 방법으로 가능
3) 그 외 데이터 암호화 방법과 데이터베이스의 접근 통제 방법이 존재
4) 데이터 암호화 : 외부로부터의 공격 또는 내부자의 불법행위로 인한 데이터 유출을 방지하기 위해 DB내에 저장된 데이터를 해독 불가능한 형식의 암호문으로 저장하는 행위
개인키 암호화 일고리즘 DES (암호화키 = 복호화키)
1) 동일한 키를 이용하는 방식
2) 보안 수준이 낮음
3) 알고리즘이 단순하고 빠름
공개키 암호화 알고리즘 RSA (암호화키 <> 복호화키)
1) 서로 다른 키를 사용하는 비대칭 암호화 방식
2) 보안 수준이 높음
3) 알고리즘이 복잡하고 느림
4) 파일 크기가 큼

23. DB 암호화 방식
1) 디스크 전체를 암호화하거나 암호화 대상이 되는 기밀정보를 담고 있는 칼럼 레벨로 암호화
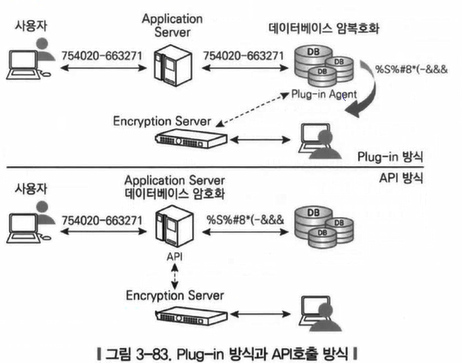
2) 칼럼 레벨 암호화의 경우 기존 legacy 애플리케이션의 수정이 필요없는 plug-in 방식과 애플리케이션의 수정이 필요한 api 방식이 사용
24. 디스크 전체(storage level) 암호화
1) db 파일을 보호하고 비인가 사용자에 의한 불법적인 파일 열람을 제한
2) 인가된 서버만이 정상적인 암호화된 데이터를 해독하고 열람할 수 있게 하는 것으로 db 암호화중 가장 편한 방법
3) 인가된 호스트 서버에 접속하는 다양한 시스템들과 사용자들을 식별하지 못하기 떔누에 칼럼 레벨의 암호화가 요구

25. 칼럼 레벨 암호화(column level) 암호화
1) 개인정보나 기업의 민감한 정보를 담고 있는 특정 테이블의 칼럼만을 암호화
2) db에서버에 접속하는 사용자들을 구분하고 정의된 암복호와 정책에 따라 데이터를 제공하기에 db 암호화중 현장에서 가장 널리 사용
3) 플러그인 방식과 API 호출방식이 존재
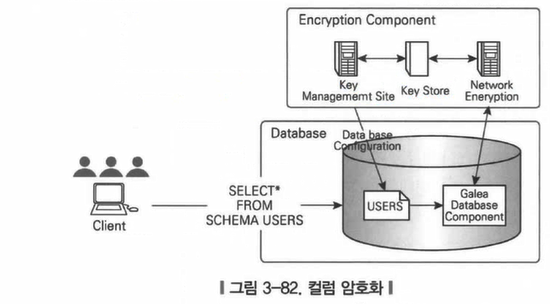
4) 플러그 인 : DB 서버내에 플러그 인을 장착하여 암복호화를 수행
5) APUI 호출 : 애플리에킹션 서버가 압복호화를 위한 API를 호출하여 수행
6) DB 서버의 자원 사용량, 속도 개선, 기존 애플리케이션의 수정 여부에 따라 두 방법 중 선택
26. 접근 통제
1) 저장된 데이터에 대해 사용자별 접근권한에 따라 접근을 제한하기 위한 기술
2) 데이터베이스의 보안을 구현하는 방법으로 접근 제어 방법을 사용
3) 보안 정책에 따라 접근 객체에 대한 접근 주체의 접근 권한 확인 및 이를 기반으로 한 접근 제어를 통해 자원에 대한 비인가된 사용을 방지하는 기능
4) 접근 통제 유형 : 임의 접근 통제, 강제 접근 통제, 역할기반 접근 통제
27. 임의 접근 통제
1) DAC, discretionary access control
2) 시스템 객체에 대한 접근을 사용자 개인 또는 그르ㅜㅂ의 식별자를 기반으로 제한
3) 주체와 객체의 신분 및 임의적 접근 통제 규칙에 기초하여 객체에 대한 주체의 접근을 통제
4) 통제 권한이 주체에 있음
5) 주체가 임의적으로 접근 통제 권한을 배분하여 제어 가능
6) = 신원 기반 정책 : grant revoke
28. 강제 접근 통제
1) MAC, mandatory access control
2) 정보시스템 내에서 어떤 주체가 특정 객체에 접근하려 할 때 양쪽의 보안 레이블에 기초하여 높은 보안 수준을 요ㅕ구하는 정보가 낮은 보안 수준의 주체에게 노출되지 않도록 접근을 제한하는 통제방법
3) 통제 권한이 제 3자에게 있음
4) 주체는 접근 통제 권한과 무관
5) = 규칙 기반 정책
29. 역할기반 접근 통제
1) RBAC, role based access control
2) 사용자가 주어진 역할에 대한 접근 권한을 부여받는 방식
3) 사용자가 바뀌어도 역할에는 변함 없음
4) db 작업 권한 통제
5) 운영체제 직업 권한 통제
6) = 역할 기반 정책 : 직책에 권한 부여
30. 접근 통제와 dcl의 관계
1) 접근 통제 정책 가운데 dbms에서 채택한 접근 통제 정책은 임의 접근 통제 방식
2) 접근 통제 용도로 sql에서 사용하는 명령어는 dcl
31. db 접근 통제 구성방법
1) 에이전트 방법, 게이트웨이 방법, 스니핑 방법
2) 하나의 단일 방식으로 구성하기도 하지만 각 방식마다 장점을 취하고 단점을 보완하기 위해 여러 가지 방식을 혼합한 하이브리드 방식을 많이 사용
3) 일반적으로 에이전트+스니핑, 게이트웨이+스니핑, 게이트웨이+에이전트+스니핑
32. 게이트웨이
1) dmbs에 접속하기 위한 통로를 별도로 설치한 후 db 사용자가 해당 통로를 통해서만 접근하도록 하는 방식
2) 프록시 게이트웨이
1] 별도의 서버(안정성을 위해 이중화)를 설치한 후 독립적인 ip 및 포트를 부여하고 db로그인 시 해당 ip 및 포트로 로그인
2] 게이트웨이를 거치도록 구성된 사용자들만 게이트웨이를 거치기 떄문에 애플리케이션 서버는 프록시 게이트웨이를 거치지 않음

3) 인라인 게이트웨이
1] 별도의 장치에 의해 모든 패킷이 자동으로 게이트웨이를 거치는 방식
2] 애플리케이션 서버에서 오는 패킷도 게이트웨이를 거치게 되어 속도 저하가 발생하고 장애 발생 시 업무 시스템에 대한 영향이 존재

33. 스니핑 방식
1) db사용자와 dbms 서버간에 주고받는 패킷을 복사하여 db 접근 제어 서버에 전달하는 방식
2) 패킷 분석 로깅(사후 감시에 의미를 두는 보안 방식)
3) dbms 서버의 패킷 흐름에 전혀 영향을 주지 않아 성능 저하 등의 문제가 발생하지 않음

스니핑 : 네트워크의 중간에서 남의 패킷 정보를 도청하는 해킹
34. 에이전트 방식
1) db 서버에 접근제어를 설치하는 방식

35. 하이브리드 방식
1) 위 방식을 모두 더한 것
36. 비교

37. 접근 통제 매커니즘
1) 접근 통제 정책을 구현하는 기술적인 방법
2) 암호화 : 평문을 암호문으로 변환
3) 패스워드 : 주체가 자신임을 증명하는 인증법
4) 보안 등급 :주체나객체 등에 부여된 보안 속성의 집합 = 강제 접근 통제(mac)
5) 권한 리스트 : 주체를 기준으로 주체에게 허가된 자원 및 권한을 기록한 목록

6) 접근 제어 리스트 : 객체를 기준으로 특정 객체에 대해 어떤 주체가 어떤 행위를 할 수 있는지를 기록한 목록

'자격증 > 정보처리기사 4과목' 카테고리의 다른 글
| 4-16강. 물리 데이터베이스 설계-물리 데이터베이스 모델링 (0) | 2020.05.09 |
|---|---|
| 4-15강.물리 데이터베이스 설계-데이터베이스 물리속성 설계 (0) | 2020.05.09 |
| 4-13강. 논리 데이터베이스 설계-데이터 모델링 및 설계(2) (0) | 2020.05.06 |
| 4-12강. 논리 데이터베이스 설계-데이터 모델링 및 설계(1) (1) | 2020.05.06 |
| 4-11강 논리 데이터베이스 설계-데이터 모델(2) (0) | 2020.05.06 |



